2016
09-26
09-26
Django基础教程(一) NEW
 前戏python Web程序众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端。#!/usr/bin/env python
#coding:utf-8
import socket
def handle_request(client):
buf = client.recv(1024)
&nb...
Read More >
前戏python Web程序众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端。#!/usr/bin/env python
#coding:utf-8
import socket
def handle_request(client):
buf = client.recv(1024)
&nb...
Read More >
前戏python Web程序众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端。#!/usr/bin/env python
#coding:utf-8
import socket
def handle_request(client):
buf = client.recv(1024)
&nb...
Read More >
前戏python Web程序众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端。#!/usr/bin/env python
#coding:utf-8
import socket
def handle_request(client):
buf = client.recv(1024)
&nb...
Read More >
 步骤如下:1、配置Apache配置文件httpd.conf :设置好CGI目录:ScriptAlias /cgi-bin/ "F:/web/cgi-bin/"配置如下:<Directory "F:/web/cgi-bin"> AllowOverride None Options FollowSymLinks +ExecCGI Order allow...
Read More >
步骤如下:1、配置Apache配置文件httpd.conf :设置好CGI目录:ScriptAlias /cgi-bin/ "F:/web/cgi-bin/"配置如下:<Directory "F:/web/cgi-bin"> AllowOverride None Options FollowSymLinks +ExecCGI Order allow...
Read More >
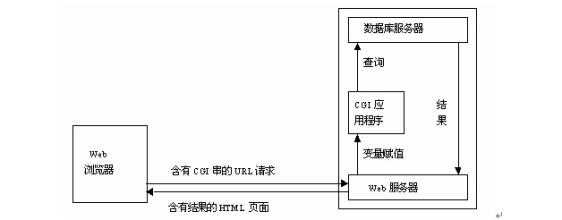 Python的“Web服务器模块”有如下三种一、SimpleHTTPServer:包含执行GET和HEAD请求的SimpleHTTPRequestHandler类。通过下面命令我们创建了HTTP服务,默认使用8000端口号监听。通过:http://localhost:8000/ 就可以访问,如果文件夹下有index.html,那么这个文件就会成为一个默认页,如果没有这个文件,那么,目录列表就会显示出来。python -m SimpleHTTPS...
Read More >
Python的“Web服务器模块”有如下三种一、SimpleHTTPServer:包含执行GET和HEAD请求的SimpleHTTPRequestHandler类。通过下面命令我们创建了HTTP服务,默认使用8000端口号监听。通过:http://localhost:8000/ 就可以访问,如果文件夹下有index.html,那么这个文件就会成为一个默认页,如果没有这个文件,那么,目录列表就会显示出来。python -m SimpleHTTPS...
Read More >
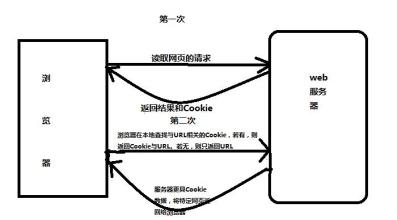
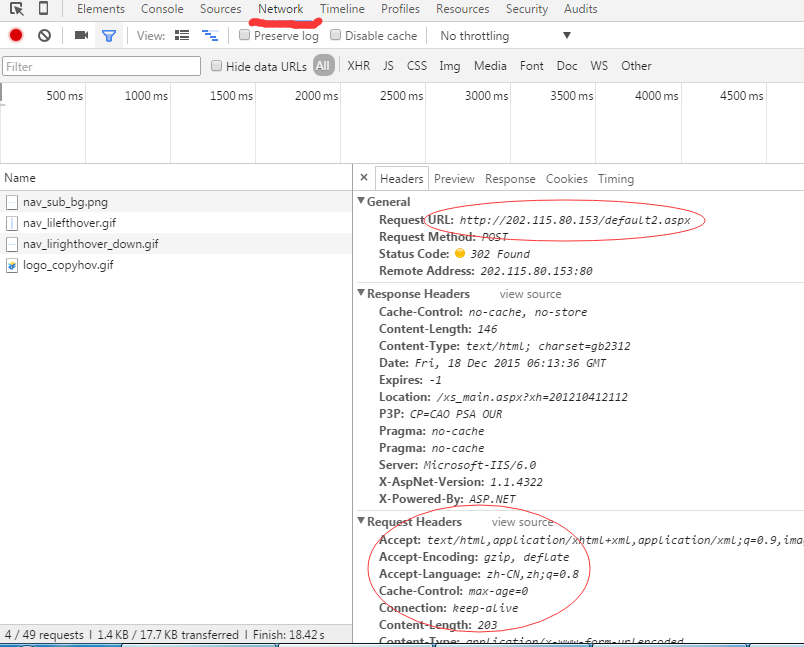 Cookie的工作原理:
Cookie由服务端生成,然后发送给浏览器,浏览器会将Cookie保存在某个目录下的文本文件中。在下次请求同一网站时,会发送该Cookie给服务器,这样服务器就知道该用户是否合法以及是否需要重新登录。
Python提供了基本的cookielib库,在首次访问某页面时,cookie便会自动保存下来,之后访问其它页面便都会带有正常登录的Cookie了。爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法。python提供了强大的u...
Read More >
Cookie的工作原理:
Cookie由服务端生成,然后发送给浏览器,浏览器会将Cookie保存在某个目录下的文本文件中。在下次请求同一网站时,会发送该Cookie给服务器,这样服务器就知道该用户是否合法以及是否需要重新登录。
Python提供了基本的cookielib库,在首次访问某页面时,cookie便会自动保存下来,之后访问其它页面便都会带有正常登录的Cookie了。爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法。python提供了强大的u...
Read More >
 先看下大家都了解的登录网站方式:# -*- coding: utf-8 -*-
# !/usr/bin/python
import urllib2
import urllib
import cookielib
import re
auth_url = 'http://www.nowamagic...
Read More >
先看下大家都了解的登录网站方式:# -*- coding: utf-8 -*-
# !/usr/bin/python
import urllib2
import urllib
import cookielib
import re
auth_url = 'http://www.nowamagic...
Read More >
 urllib2.urlopen()函数不支持验证、cookie或者其它HTTP高级功能。要支持这些功能,必须使用build_opener()函数创建自定义Opener对象。语法如下:build_opener([handler1 [ handler2, ... ]]) 参数handler是Handler实例,常用的有HTTPBasicAuthHandler、HTTPCookieProcessor、ProxyHandl...
Read More >
urllib2.urlopen()函数不支持验证、cookie或者其它HTTP高级功能。要支持这些功能,必须使用build_opener()函数创建自定义Opener对象。语法如下:build_opener([handler1 [ handler2, ... ]]) 参数handler是Handler实例,常用的有HTTPBasicAuthHandler、HTTPCookieProcessor、ProxyHandl...
Read More >
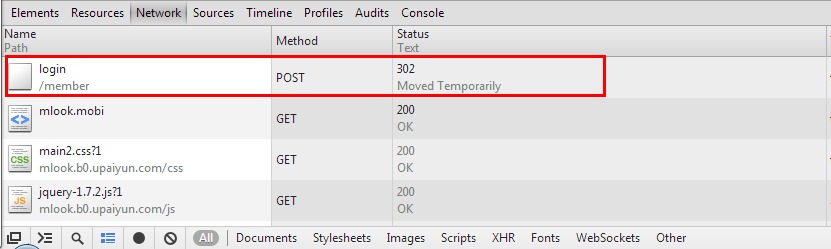 我的博客中曾经贴过几个爬虫程序的代码,用来批量下载图片非常方便。这样的爬虫实现起来比较简单。而有些网站需要用户登录之后才可以下载文件,之前的方法就办不到了。今天就说说用Python模拟浏览器的登录过程,为之后的登录下载做好准备。登录的情况,需要额外用到的一个模块是cookielib,用来记住登录成功之后保存到本地的cookie,方便在网站的各个页面之间穿越。先上代码示例:#encoding=utf8
import urllib
import urll...
Read More >
我的博客中曾经贴过几个爬虫程序的代码,用来批量下载图片非常方便。这样的爬虫实现起来比较简单。而有些网站需要用户登录之后才可以下载文件,之前的方法就办不到了。今天就说说用Python模拟浏览器的登录过程,为之后的登录下载做好准备。登录的情况,需要额外用到的一个模块是cookielib,用来记住登录成功之后保存到本地的cookie,方便在网站的各个页面之间穿越。先上代码示例:#encoding=utf8
import urllib
import urll...
Read More >
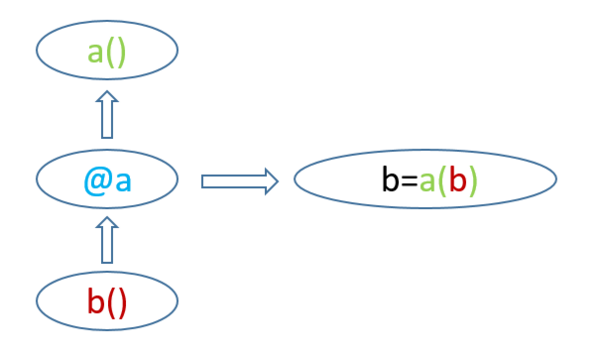 装饰器(Decorator)相对简单,咱们先介绍它:“装饰器的功能是将被装饰的函数当作参数传递给与装饰器对应的函数(名称相同的函数),并返回包装后的被装饰的函数”,听起来有点绕,没关系,直接看示意图,其中 a 为与装饰器 @a 对应的函数, b 为装饰器修饰的函数,装饰器@a的作用是: 简而言之:@a 就是将 b 传递给 a(),并返回新的 b = a(b)在python中常看到在定义函数是使用@func. 这就是装饰器, 装饰器是把一个函数作为参数的函数,常常用于...
Read More >
装饰器(Decorator)相对简单,咱们先介绍它:“装饰器的功能是将被装饰的函数当作参数传递给与装饰器对应的函数(名称相同的函数),并返回包装后的被装饰的函数”,听起来有点绕,没关系,直接看示意图,其中 a 为与装饰器 @a 对应的函数, b 为装饰器修饰的函数,装饰器@a的作用是: 简而言之:@a 就是将 b 传递给 a(),并返回新的 b = a(b)在python中常看到在定义函数是使用@func. 这就是装饰器, 装饰器是把一个函数作为参数的函数,常常用于...
Read More >